Советы для улучшения качества embedded-кода на C++
Дисклеймер: этот пост ни коим образом не является общим описанием embedded-разработки. Это небольшая хитрость, которая улучшает качество программ при работе с железом.
Embedded это восхитительный мир, позволяющий разработчикам создавать различные повседневные устройства вместе с аппаратчиками-схемотехниками.
Мотивация этой статьи достаточно проста: вокруг полно (просто до безобразия) некачественного embedded-кода. Этому есть ряд причин:
- У разработчиков отсутствует опыт и образование в области программной инженерии. Зачастую embedded-программистами становятся люди с образованием из области электро- и радиотехники, которым во время обучения преподают либо “чистый” C, либо C с классами (советую посмотреть доклад на эту тему).
- Сложность отладки. Большая часть embedded-систем достаточно слаба с точки зрения вычислительных мощностей и имеет весьма ограниченные возможности отладки (порой, они даже отсутствуют). Это не является проблемой само по себе, но может привести к большому количеству костылей, лишь бы работало, а также к индусскому коду.
- Экзотические архитектуры (с байтом в 24 или 32 бита) и зоопарк компиляторов. Раньше это были, в основном, кастомные решения, однако сейчас производители процессоров стремятся использовать GCC и LLVM в виде базы для построения тулчейна. Это приводит к проблемам при переиспользовании кода и замедляет принятие новых стандартов.
Ближе к делу, наша задача состоит в превращении подобного кода (CubeMX, STM32):
void SystemInit_ExtMemCtl(void)
{
__IO uint32_t tmp = 0x00;
register uint32_t tmpreg = 0, timeout = 0xFFFF;
register __IO uint32_t index;
RCC->AHB1ENR |= 0x000001F8;
tmp = READ_BIT(RCC->AHB1ENR, RCC_AHB1ENR_GPIOCEN);
GPIOD->AFR[0] = 0x00CCC0CC;
GPIOD->AFR[1] = 0xCCCCCCCC;
GPIOD->MODER = 0xAAAA0A8A;
GPIOD->OSPEEDR = 0xFFFF0FCF;
GPIOD->OTYPER = 0x00000000;
GPIOD->PUPDR = 0x00000000;
GPIOE->AFR[0] = 0xC00CC0CC;
GPIOE->AFR[1] = 0xCCCCCCCC;
GPIOE->MODER = 0xAAAA828A;
GPIOE->OSPEEDR = 0xFFFFC3CF;
GPIOE->OTYPER = 0x00000000;
GPIOE->PUPDR = 0x00000000;
// ...
/* Delay */
for (index = 0; index<1000; index++);
// ...
(void)(tmp);
}
Во что-то вроде этого:
void SystemInit_ExtMemCtl() {
rcc.Init();
gpio.Init();
}
Почему это вообще проблема?
Рассматриваемый код тяжело читать, понимать и поддерживать. Самое худшее, что всё перечисленное также относится и к разработчику, который сам это и написал. Переключите его на другую задачу на пару месяцев и после этого он не вспомнит, что же такое GPIOE->MODER.
Две мысли от умных людей помогут нам сделать этот код лучше:
All problems in computer science can be solved by another level of indirection
— David J. Wheeler
C++ is a zero-cost abstraction language
— Bjarne Stroustrup
Идея заключается в возможности создания и разделения уровней абстракции без потерь в производительности. В результате, компилятор оптимизирует всё высокоуровневое программирование и абстракции и сгенерирует абсолютно идентичный код. В общем случае, аппаратуру можно разделить на уровни в соответствии со следующей диаграммой:
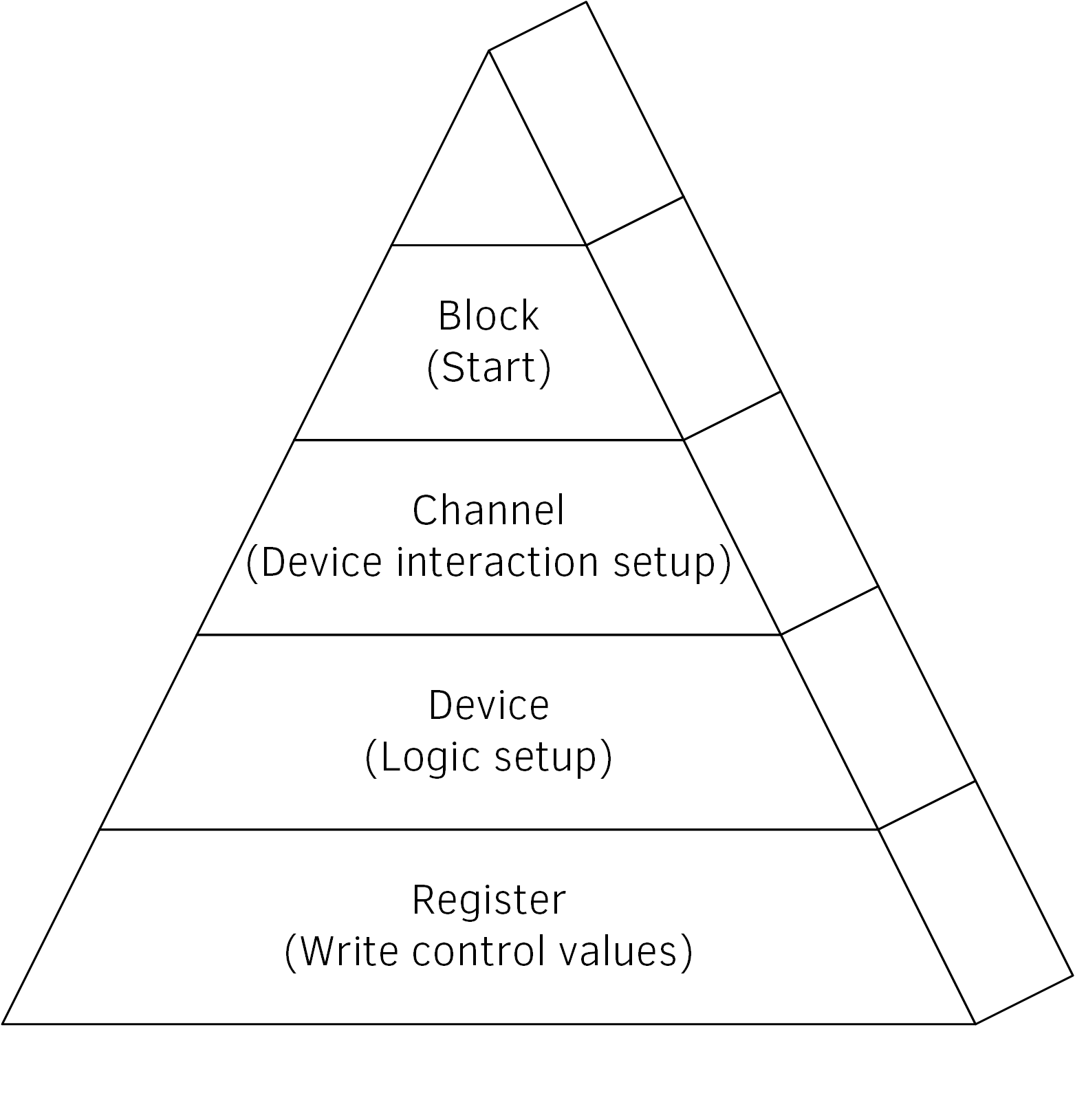
Представим, что у нас есть плата с микросхемой и наша задача состоит в настройке блока этой микросхемы. Первым делом, открываем даташит и видим что-то вроде этого:
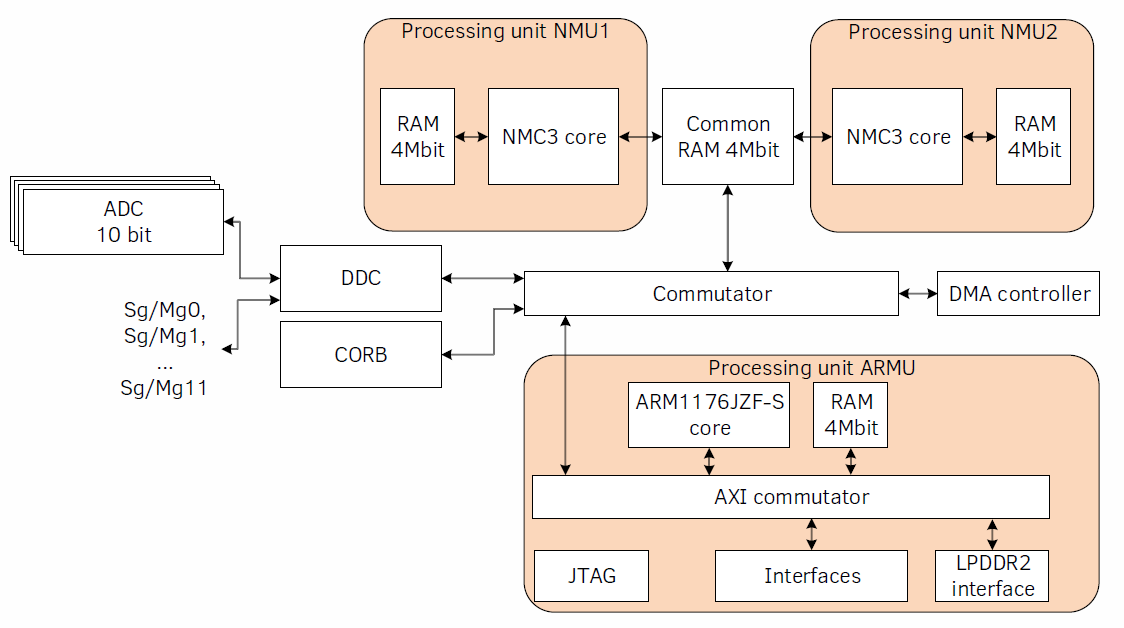
Отлично, теперь у нас есть смутное представление о микросхеме. Наша задача состоит в том, чтобы заставить блок DDC(digital down converter, очень полезная штука, часто используется в аппаратной цифровой обработке сигналов) работать так, как мы хотим. Упрощённая структурная схема приведена ниже:
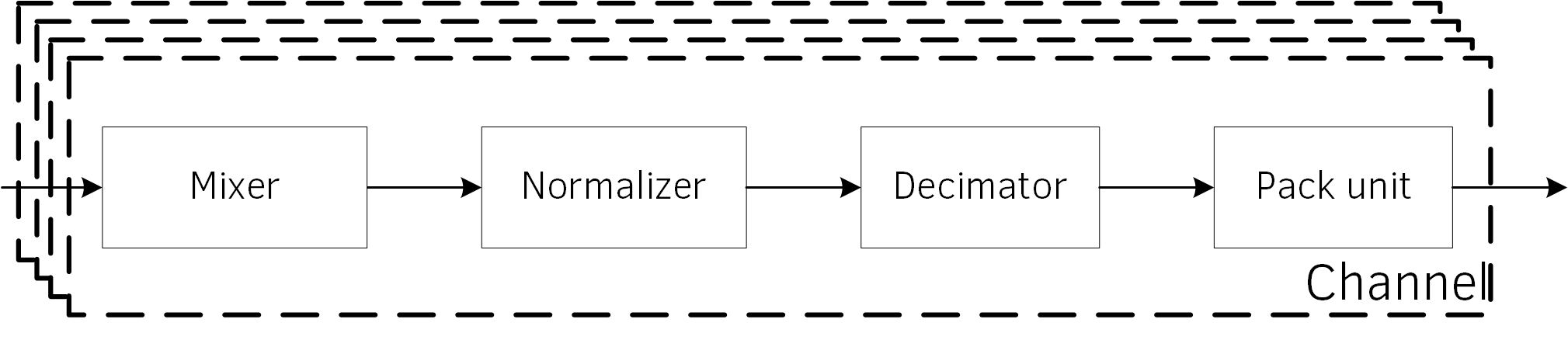
Теперь будем строить наши абстракции! В соответствии с диаграммой выше, начнём с самых низов, с самого низкого уровня. Мы начнём с регистров. Обычно, они представлены в документации в следующем виде:

Цифры сверху означают номера битов, ниже приведены названия полей. Подобное изображение регистра зачастую сопровождается таблицей с описанием полей. Стоит отметить, что работа с регистрами обычно связана с:
- Множественной работой с битовыми полями
- Возможностью смены значения регистра вне программы (аппаратное изменение)
К сожалению, большинство embedded-библиотек и кода работают с регистрами следующим образом:
*(volatile std::uint32_t*)reg_name = val;
В этом коде берётся адрес регистра, который хранится в переменной reg_name (или даже #define-константе), приводит к volatile указателю, разыменовывает его и записывает значение. Это плохо по ряду причин:
- Код сложно читать и поддерживать
- Практически отсутствует возможность для инкапсуляции и повышения уровня абстракции
- При наличии множества регистров код обычно превращается в простыню (больше того, copy-paste на радость статическому анализатору)
Однако, существует альтернатива. Рассматриваемый регистр может быть представлен в виде структуры:
struct DeviceSetup {
enum class TableType : std::uint32_t {
inphase = 0,
quadrature,
table
};
std::uint32_t input_source : 8;
TableType table_type : 4;
std::uint32_t reserved : 20;
};
В случае, если внутренние поля требуют пересчёта, он может быть скрыт и выполнен в методах GetFoo() и SetFoo(). К слову, я очень рад появлению этого предложения по разрешению инициализации по умолчанию для битовых полей.
Следующим шагом является расположение объекта структуры в соответствующее место в памяти. В зависимости от предпочтений и стиля кода, это может быть реализовано через расположение указателя, ссылки, либо используя placement new:
auto device_registers_ptr =
reinterpret_cast<DeviceSetup*>(DeviceControlAddress);
auto &device_registers_ref =
*reinterpret_cast<DeviceSetup*>(DeviceControlAddress);
auto device_registers_placement =
new (reinterpret_cast<DeviceSetup*>(DeviceControlAddress)) DeviceSetup;
Но подождите, выше я уже упоминал, что значения регистров могут быть изменены вне программы. В данной реализации, компилятор может закэшировать значение и вы будете читать одно и то же значение, что не совсем соответствует тому, что мы ожидаем увидеть.
Существует способ сказать компилятору, что значение может быть изменено, это делается при помощи volatile. Это ключевое слово зачастую используется неправильно и получило репутацию, сравнимую с goto. Но оно было введено именно для подобных ситуаций (вот тут можно ознакомиться).
volatile auto device_registers_ptr =
reinterpret_cast<DeviceSetup*>(DeviceControlAddress);
volatile auto &device_registers_ref =
*reinterpret_cast<DeviceSetup*>(DeviceControlAddress);
volatile auto device_registers_placement =
new (reinterpret_cast<DeviceSetup*>(DeviceControlAddress)) DeviceSetup;
Теперь мы можем быть уверены, что каждая операция чтения будет произведена.
N.B. Доступ к регистрам, которые модифицируются извне, может быть рассмотрен как многопоточное приложение. Следовательно, стоит рассмотреть возможность использования
std::atomic<T*>вместоvolatile T*. К сожалению, используемые нами копиляторы полностью не поддерживают C++11 (NM SDK выполнен по стандарту C++98 с полным отсутствием STL, ARM Compiler 5 поддерживает C++11 на уровне синтаксиса, но STL осталась от старой версии компилятора), поэтому я не могу протестировать это решение в реальных условиях. Однако, compiler explorer демонстрирует многообещающий дизассемблер: ссылка.
Отлично, с регистрами всё, пора добавить новый уровень абстракции: давайте настроим устройство. В большинстве случаев, устройство может быть представлено как набор регистров или других устройств:
struct Mixer {
NCO nco;
MixerInput mixer_input;
// ...
};
Разработчикам следует написать общий метод настройки, а также методы доступа к составным устройствам для более тонкой настройки.
NCO& GetNCO() {
return nco;
}
Повышаем уровень абстракции и создаём канал, состоящий из устройств:
struct Channel{
Mixer mixer;
Normalizer normalizer;
Downsampler downsampler;
PackUnit pack_unit;
};
И, наконец-то, весь блок может быть представлен как массив каналов и ряд управляющих регистров:
struct DDC {
std::array<Channel, number_of_channels> channels;
struct ControlRegisters {
// ...
} control_registers;
};
Это всё называется уровнем абстракций над аппаратурой (HAL). Этот уровень предоставляет программный интерфейс взаимодействия с железом. Самая удобная вещь в применении HAL заключается в возможности подмены реальной аппаратурой на ПК-модель. Это отдельная тема для разговора и другой статьи. Вкратце, преимущества моделей:
- Модели позволяют разработчикам писать программы без непосредственной работы с аппаратурой. Это очень полезно, так как позволяет разрабатывать ПО в процессе изготовления микросхем или плат и, тем самым, уменьшая время вывода продукта на рынок
- Реализация моделей позволяет улучшить понимание аппаратуры, над которой трудится программист
- Модели позволяют отлаживать программы в post-mortem режиме. Для этого собирается дамп памяти, либо некая другая информация и модель запускается с этими данными.
В этой статье я попытался убедить вас, что низкоуровневый код может быть написан в хорошем стиле и не причинять страдания людям, которые будут с ним в дальнейшем работать.